Spark-IDEA环境搭建并测试
本文最后更新于:May 13, 2023 pm
Apache Spark 是一个快速的,通用的集群计算系统。它对 Java,Scala,Python 和 R 提供了的高层 API,并有一个经优化的支持通用执行图计算的引擎。它还支持一组丰富的高级工具,包括用于 SQL 和结构化数据处理的 Spark SQL,用于机器学习的 MLlib,用于图计算的 GraphX 和 Spark Streaming。
目录
- 创建一个Maven项目
- 安装插件
在IDEA中搜索 scala插件并进行安装。
- 添加scala
打开Project Structure,并在左侧中,找到Global Libraries。点击加号(+)进行添加scala,没有的则在弹出的小窗口左下角点击Download进行下载,再选择版本即可。
- 在项目的栏,选择项目文件右键,选择
Add Frameworks Support,在窗口左侧找到 Scala并勾上,右侧就会自动找到你刚才下载的Scala,没有就手动点击Create进行下载或者选择。再点OK。
测试环境
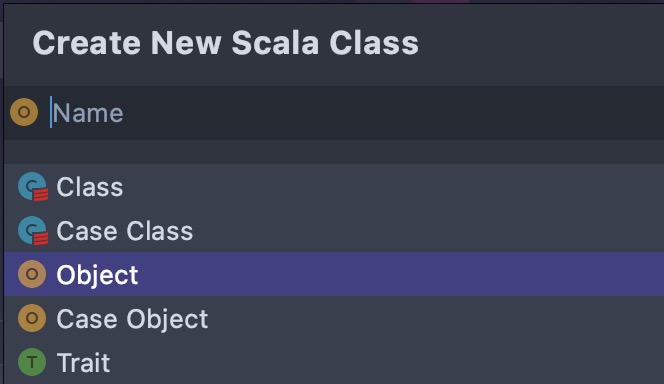
在main/java文件夹中创建一个Scala Class(和正常创建java class一样,只是选择的时候选择Scala Class即可)。更重要的是创建的是Object,而不是Class。如果创建的是Class,则不能运行,只有创建的是Object才可以运行。如图。
完整代码如下:
1 | |
当控制台上有输出时,则表示环境搭建成功。
Spark依赖(选择)
现在可以不用加,后面有需要的地方再加就行。
把Spark依赖添加到Maven的pom.xml文件里。 注意Spark的artifacts使用Scala版本进行标记。
1 | |
本文作者: 墨水记忆
本文链接: https://tothefor.com/DragonOne/2246675075.html
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
