本文最后更新于:April 11, 2022 pm
本文内容:读写锁 ReentrantReadWriteLock 的源码分析,基于 Java7/Java8。
阅读建议:虽然我这里会介绍一些 AQS 的知识,不过如果你完全不了解 AQS,看本文就有点吃力了。
目录 使用示例 下面这个例子非常实用,我是 javadoc 的搬运工:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class CachedData volatile boolean cacheValid;final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();void processCachedData () if (!cacheValid) { try {if (!cacheValid) { true ;finally {try {finally {
ReentrantReadWriteLock 分为读锁和写锁两个实例,读锁是共享锁,可被多个线程同时使用,写锁是独占锁。持有写锁的线程可以继续获取读锁,反之不行。
ReentrantReadWriteLock 总览 这一节比较重要,我们要先看清楚 ReentrantReadWriteLock 的大框架,然后再到源码细节。
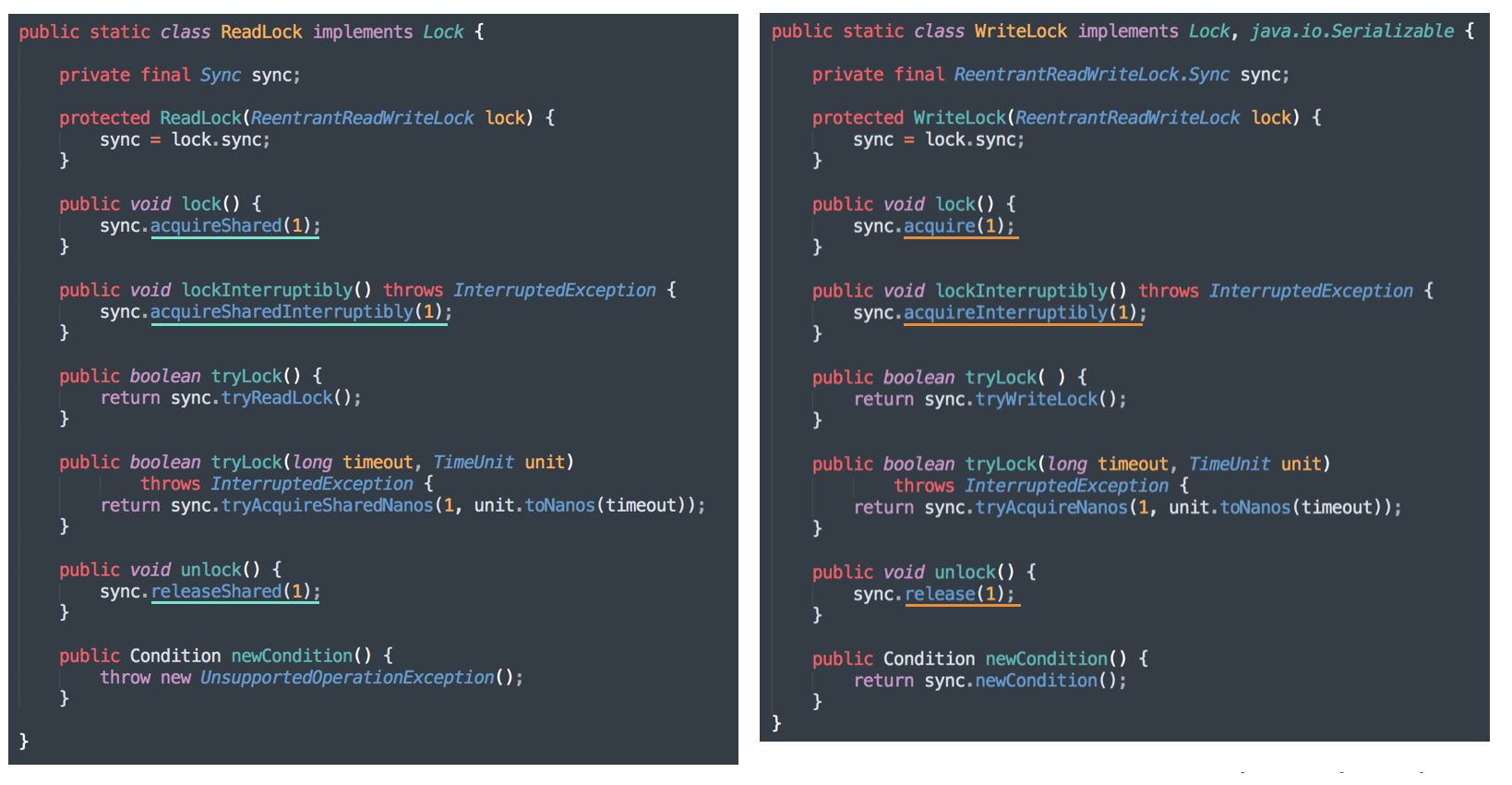
首先,我们来看下 ReentrantReadWriteLock 的结构,它有好些嵌套类:
大家先仔细看看这张图中的信息。然后我们把 ReadLock 和 WriteLock 的代码提出来一起看,清晰一些:
很清楚了,ReadLock 和 WriteLock 中的方法都是通过 Sync 这个类来实现的。Sync 是 AQS 的子类,然后再派生了公平模式和不公平模式。
从它们调用的 Sync 方法,我们可以看到: ReadLock 使用了共享模式,WriteLock 使用了独占模式 。
等等,同一个 AQS 实例怎么可以同时使用共享模式和独占模式 ???
这里给大家回顾下 AQS,我们横向对比下 AQS 的共享模式和独占模式:
AQS 的精髓在于内部的属性 state :
对于独占模式来说,通常就是 0 代表可获取锁,1 代表锁被别人获取了,重入例外
而共享模式下,每个线程都可以对 state 进行加减操作
也就是说,独占模式和共享模式对于 state 的操作完全不一样,那读写锁 ReentrantReadWriteLock 中是怎么使用 state 的呢?答案是将 state 这个 32 位的 int 值分为高 16 位和低 16位,分别用于共享模式和独占模式 。
源码分析 有了前面的概念,大家心里应该都有数了吧,下面就不再那么啰嗦了,直接代码分析。
源代码加注释 1500 行,并不算难,我们要看的代码量不大。如果你前面一节都理解了,那么直接从头开始一行一行往下看就是了,还是比较简单的。
ReentrantReadWriteLock 的前面几行很简单,我们往下滑到 Sync 类,先来看下它的所有的属性:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 abstract static class Sync extends AbstractQueuedSynchronizer static final int SHARED_SHIFT = 16 ;static final int SHARED_UNIT = (1 << SHARED_SHIFT);static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1 ;static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1 ;static int sharedCount (int c) return c >>> SHARED_SHIFT; }static int exclusiveCount (int c) return c & EXCLUSIVE_MASK; }static final class HoldCounter int count = 0 ;final long tid = getThreadId(Thread.currentThread());static final class ThreadLocalHoldCounter extends ThreadLocal <HoldCounter > {public HoldCounter initialValue () return new HoldCounter();private transient ThreadLocalHoldCounter readHolds;private transient HoldCounter cachedHoldCounter;private transient Thread firstReader = null ;private transient int firstReaderHoldCount;new ThreadLocalHoldCounter();
state 的高 16 位代表读锁的获取次数,包括重入次数,获取到读锁一次加 1,释放掉读锁一次减 1
state 的低 16 位代表写锁的获取次数,因为写锁是独占锁,同时只能被一个线程获得,所以它代表重入次数
每个线程都需要维护自己的 HoldCounter,记录该线程获取的读锁次数,这样才能知道到底是不是读锁重入,用 ThreadLocal 属性 readHolds 维护
cachedHoldCounter 有什么用?其实没什么用,但能提示性能。将最后一次获取读锁的线程的 HoldCounter 缓存到这里,这样比使用 ThreadLocal 性能要好一些,因为 ThreadLocal 内部是基于 map 来查询的。但是 cachedHoldCounter 这一个属性毕竟只能缓存一个线程,所以它要起提升性能作用的依据就是:通常读锁的获取紧随着就是该读锁的释放。我这里可能表达不太好,但是大家应该是懂的吧。firstReader 和 firstReaderHoldCount 有什么用?其实也没什么用,但是它也能提示性能。将”第一个”获取读锁的线程记录在 firstReader 属性中,这里的第一个 不是全局的概念,等这个 firstReader 当前代表的线程释放掉读锁以后,会有后来的线程占用这个属性的。firstReader 和 firstReaderHoldCount 使得在读锁不产生竞争的情况下,记录读锁重入次数非常方便快速 如果一个线程使用了 firstReader,那么它就不需要占用 cachedHoldCounter
个人认为,读写锁源码中最让初学者头疼的就是这几个用于提升性能的属性了,使得大家看得云里雾里的。主要是因为 ThreadLocal 内部是通过一个 ThreadLocalMap 来操作的,会增加检索时间。而很多场景下,执行 unlock 的线程往往就是刚刚最后一次执行 lock 的线程,中间可能没有其他线程进行 lock。还有就是很多不怎么会发生读锁竞争的场景。
上面说了这么多,是希望能帮大家降低后面阅读源码的压力,大家也可以先看看后面的,然后再慢慢体会。
前面我们好像都只说读锁,完全没提到写锁,主要是因为写锁真的是简单很多,我也特地将写锁的源码放到了后面,我们先啃下最难的读锁先。
读锁获取 下面我就不一行一行按源码顺序说了,我们按照使用来说。
我们来看下读锁 ReadLock 的 lock 流程:
public void lock () 1 );public final void acquireShared (int arg) if (tryAcquireShared(arg) < 0 )
然后我们就会进到 Sync 类的 tryAcquireShared 方法:
在 AQS 中,如果 tryAcquireShared(arg) 方法返回值小于 0 代表没有获取到共享锁(读锁),大于 0 代表获取到
回顾 AQS 共享模式:tryAcquireShared 方法不仅仅在 acquireShared 的最开始被使用,这里是 try,也就可能会失败,如果失败的话,执行后面的 doAcquireShared,进入到阻塞队列,然后等待前驱节点唤醒。唤醒以后,还是会调用 tryAcquireShared 进行获取共享锁的。当然,唤醒以后再 try 是很容易获得锁的,因为这个节点已经排了很久的队了,组织是会照顾它的。
所以,你在看下面这段代码的时候,要想象到两种获取读锁的场景,一种是新来的,一种是排队排到它的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 protected final int tryAcquireShared (int unused) int c = getState();if (exclusiveCount(c) != 0 &&return -1 ;int r = sharedCount(c);if (!readerShouldBlock() &&if (r == 0 ) {1 ;else if (firstReader == current) {else {if (rh == null || rh.tid != getThreadId(current))else if (rh.count == 0 ) return 1 ;return fullTryAcquireShared(current);
上面的代码中,要进入 if 分支,需要满足:readerShouldBlock() 返回 false,并且 CAS 要成功(我们先不要纠结 MAX_COUNT 溢出)。
那我们反向推,怎么样进入到最后的 fullTryAcquireShared:
readerShouldBlock() 返回 true,2 种情况:
compareAndSetState(c, c + SHARED_UNIT) 这里 CAS 失败,存在竞争。可能是和另一个读锁获取竞争,当然也可能是和另一个写锁获取操作竞争。
然后就会来到 fullTryAcquireShared 中再次尝试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 final int fullTryAcquireShared (Thread current) null ;for (;;) {int c = getState();if (exclusiveCount(c) != 0 ) {if (getExclusiveOwnerThread() != current)return -1 ;else if (readerShouldBlock()) {if (firstReader == current) {else {if (rh == null ) {if (rh == null || rh.tid != getThreadId(current)) {if (rh.count == 0 )if (rh.count == 0 )return -1 ;if (sharedCount(c) == MAX_COUNT)throw new Error("Maximum lock count exceeded" );if (compareAndSetState(c, c + SHARED_UNIT)) {if (sharedCount(c) == 0 ) {1 ;else if (firstReader == current) {else {if (rh == null )if (rh == null || rh.tid != getThreadId(current))else if (rh.count == 0 )return 1 ;
firstReader 是每次将读锁获取次数 从 0 变为 1 的那个线程。
能缓存到 firstReader 中就不要缓存到 cachedHoldCounter 中。
上面的源码分析应该说得非常详细了,如果到这里你不太能看懂上面的有些地方的注释,那么可以先往后看,然后再多看几遍。
读锁释放 下面我们看看读锁释放的流程:
public void unlock () 1 );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 public final boolean releaseShared (int arg) if (tryReleaseShared(arg)) {return true ;return false ;protected final boolean tryReleaseShared (int unused) if (firstReader == current) {if (firstReaderHoldCount == 1 )null ;else else {if (rh == null || rh.tid != getThreadId(current))int count = rh.count;if (count <= 1 ) {if (count <= 0 )throw unmatchedUnlockException();for (;;) {int c = getState();int nextc = c - SHARED_UNIT;if (compareAndSetState(c, nextc))return nextc == 0 ;
读锁释放的过程还是比较简单的,主要就是将 hold count 减 1,如果减到 0 的话,还要将 ThreadLocal 中的 remove 掉。
然后是在 for 循环中将 state 的高 16 位减 1,如果发现读锁和写锁都释放光了,那么唤醒后继的获取写锁的线程。
写锁获取
写锁是独占锁。
如果有读锁被占用,写锁获取是要进入到阻塞队列中等待的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public void lock () 1 );public final void acquire (int arg) if (!tryAcquire(arg) &&protected final boolean tryAcquire (int acquires) int c = getState();int w = exclusiveCount(c);if (c != 0 ) {if (w == 0 || current != getExclusiveOwnerThread())return false ;if (w + exclusiveCount(acquires) > MAX_COUNT)throw new Error("Maximum lock count exceeded" );return true ;if (writerShouldBlock() ||return false ;return true ;
下面看一眼 writerShouldBlock() 的判定,然后你再回去看一篇写锁获取过程。
static final class NonfairSync extends Sync final boolean writerShouldBlock () return false ; static final class FairSync extends Sync final boolean writerShouldBlock () return hasQueuedPredecessors();
写锁释放 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public void unlock () 1 );public final boolean release (int arg) if (tryRelease(arg)) {if (h != null && h.waitStatus != 0 )return true ;return false ;protected final boolean tryRelease (int releases) if (!isHeldExclusively())throw new IllegalMonitorStateException();int nextc = getState() - releases;boolean free = exclusiveCount(nextc) == 0 ;if (free)null );return free;
看到这里,是不是发现写锁相对于读锁来说要简单很多。
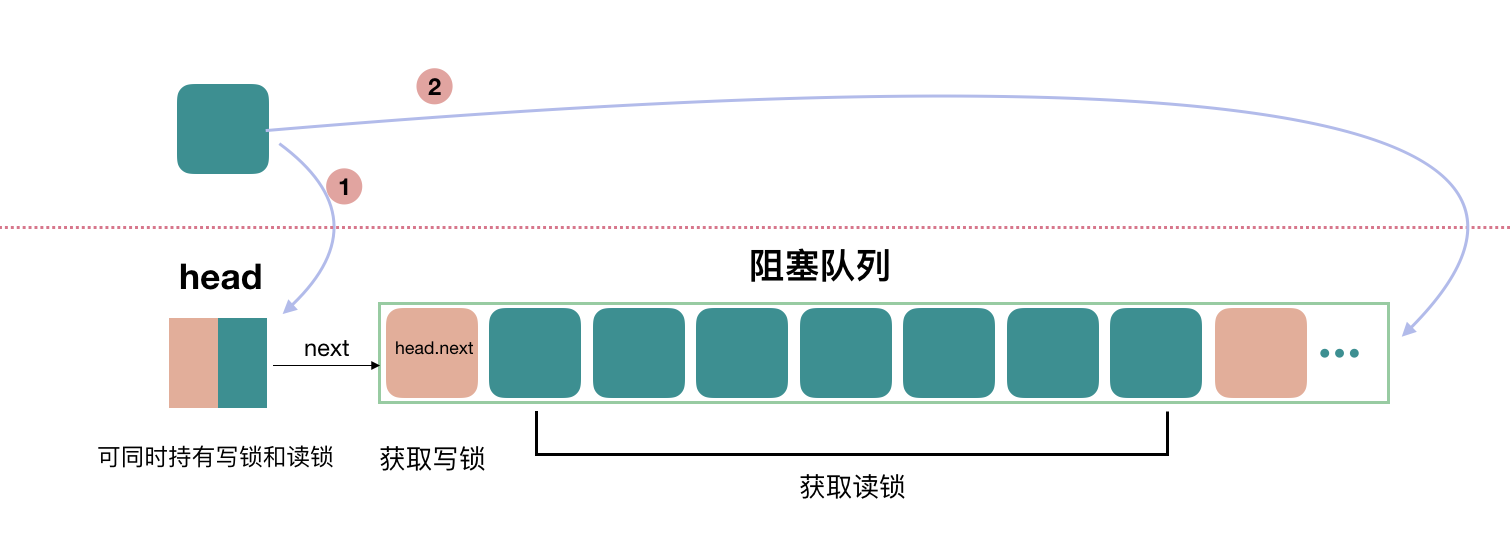
锁降级 Doug Lea 没有说写锁更高级 ,如果有线程持有读锁,那么写锁获取也需要等待。
不过从源码中也可以看出,确实会给写锁一些特殊照顾,如非公平模式下,为了提高吞吐量,lock 的时候会先 CAS 竞争一下,能成功就代表读锁获取成功了,但是如果发现 head.next 是获取写锁的线程,就不会去做 CAS 操作。
Doug Lea 将持有写锁的线程,去获取读锁的过程称为锁降级(Lock downgrading) 。这样,此线程就既持有写锁又持有读锁。
但是,锁升级 是不可以的。线程持有读锁的话,在没释放的情况下不能去获取写锁,因为会发生死锁 。
回去看下写锁获取的源码:
protected final boolean tryAcquire (int acquires) int c = getState();int w = exclusiveCount(c);if (c != 0 ) {if (w == 0 || current != getExclusiveOwnerThread())return false ;
仔细想想,如果线程 a 先获取了读锁,然后获取写锁,那么线程 a 就到阻塞队列休眠了,自己把自己弄休眠了,而且可能之后就没人去唤醒它了。
总结