Redis学习笔记(三)三大特殊数据类型
本文最后更新于:December 3, 2021 pm
Redis 是当前互联网世界最为流行的 NoSQL(Not Only SQL)数据库。Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,并提供多种语言的 API。Redis 具备一定持久层的功能,也可以作为一种缓存工具。对于 NoSQL 数据库而言,作为持久层,它存储的数据是半结构化的,这就意味着计算机在读入内存中有更少的规则,读入速度更快。Redis 通常被称为数据结构服务器,因为值(value)可以是字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets)等类型。
目录
1.地理空间(geospatial)
Geospatial是Redis在3.2版本以后增加的地理位置GEO模块,加入了地理空间(geospatial)以及索引半径查询的功能。这个模块可以用来实现微信附近的人,在线点餐“附近的餐馆”等位置功能。主要用在需要地理位置的应用上。
1.1 GEOADD
时间复杂度:每一个元素添加是O(log(N)) ,N是sorted set的元素数量。
将指定的地理空间位置(维度、经度、名字)添加到指定的键里面,数据以有序集合的形式被存放在键中。GEOADD接收的参数必须先输入经度,然后输入维度,经度必须在纬度之前。
- 有效的经度从-180°到180°。
- 有效的纬度从-85.05112878°到85.05112878°。
当坐标位置超出上述指定范围时,该命令将会返回一个错误。
GEOADD key longitude latitude member [longitude latitude member …]
示例:
1 | |
1.2 GEOPOS
根据键(key)获取给定位置元素的经度和纬度。
GEOPOS key member [member …]
示例:
1 | |
1.3 GEODIST
返回两个给定位置之间的距离,以双精度浮点数的形式被返回。如果给定的位置其中一个不存在(两个都不存在也是一样),将会返回空值(nil)。
GEODIST key member1 member2 [unit]
其中,unit是单位,如下:
- m 表示单位为米。默认情况。
- km 表示单位为千米。
- mi 表示单位为英里。
- ft 表示单位为英尺。
注意:GEODIST 计算的算法会将地球考虑为一个完全球体,在极限情况下,存在最大0.5%的误差
示例:
1 | |
1.4 GEORADIUS
以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。即:求以给定的位置为中心,以给定的半径画圆,求有多少在圈里面。
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count]
GEORADIUS 的返回值是一个数组,但是数组的内容会根据是否存在上述参数而改变。
其中:
[WITHCOORD] [WITHDIST] [WITHHASH]选项:(可多选)
- [WITHCOORD]:将位置元素的经度和纬度也一并返回。
- [WITHDIST] :在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。
- [WITHHASH]: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
[ASC|DESC] 选项:
- ASC:根据给定的中心位置,从近到远返回位置元素。
- DESC:根据给定的中心位置,从远到近返回位置元素。(默认情况)
GEORADIUS 默认会返回符合条件的全部位置元素。但是用户可以通过[COUNT count] 参数去指定获取前N个匹配元素。
示例:
1 | |
1.5 GEORADIUSBYMEMBER
GEORADIUSBYMEMBER与GEORADIUS的区别在于,GEORADIUSBYMEMBER无需给定经纬度,只需要给定成员的key就行,具体使用与GEORADIUS一致。
示例:
1 | |
1.6 GEOHASH
返回一个或多个位置元素的 Geohash 表示。通常使用表示位置的元素使用不同的技术,使用Geohash位置52点整数编码。由于编码和解码过程中所使用的初始最小和最大坐标不同,编码的编码也不同于标准。此命令返回一个标准的Geohash。该命令将返回11个字符的Geohash字符串。
GEOHASH key member [member …]
1 | |
2.HyperLogLog
HyperLogLog是用来做基数统计的算法,它提供不精确的去重计数方案,标准误差是0.81%,对于UV这种统计来说这样的误差范围是被允许的。HyperLogLog的优点在于,输入元素的数量或者体积非常大时,基数计算的存储空间是固定的。在Redis中,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2^64个不同的基数。但是,HyperLogLog只能统计基数的大小(也就是数据集的大小,集合的个数),不能存储元素的本身,不能向set集合那样存储元素本身,也就是说无法返回元素。HyperLogLog指令都是PF开头的。
2.1 添加(PFADD)
PFADD key element [element …]
将任意数量的元素添加到指定的 HyperLogLog 里面,
示例:
1 | |
2.2 计数(PFCOUNT)
PFCOUNT key [key …]
统计个数。
1 | |
2.3 合并(PDMERGE)
PFMERGE destkey sourcekey [sourcekey …]
将多个HyperLogLog合并到一个HyperLogLog中,合并后HyperLogLog的基数接近于所有输入HyperLogLog的可见集合的并集。destkey是合并生成的新HyperLogLog,后面是需要合并的HyperLogLog。
1 | |
3.BitMaps
Bitmaps 称为位图,底层就是字符串(key-value),byte数组。Bitmaps 的“位数组”每个单元格只能存储0和1(两种状态),数组的下标在Bitmaps中称为偏移量。设置时key不存在会自动生成一个新的字符串,如果设置的偏移量超出了现有内容的范围,就会自动将位数组进行零扩充。简单理解就是一串二进制。
3.1 设置(setbit)
setbit key offset value
这里的key可以理解成一个数组,而offset就是下标。
示例:
1 | |
3.2 获取(getbit)
getbit key offset
就像是获取数组中的元素一样(通过下标)。
示例:
1 | |
3.3 统计(bitcount)
BITCOUNT key [start] [end]
计算给定字符串中,被设置为1的bit位的数量。start和end参数可以指定查询的范围,可以使用负数值。-1代表最后一个字节,-2代表倒是第二个字节。
注意:start和end是字节索引,因此每增加1 代表的是增加一个字符,也就是8位,所以位的查询范围必须是8的倍数。
示例:
1 | |
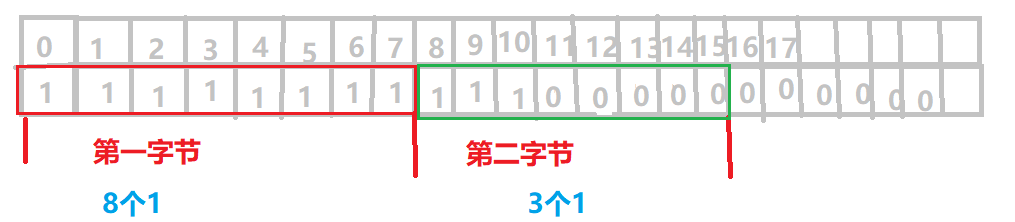
注意:设置的时候是设置的某一位的值,而一字节等于8位;所以需要8位8位的一起看,即:从0-7是第一字节,8-15是第二字节!!!而此命令的start和end是字节,所以0表示第一字节,1表示第二字节。这也是上面的注意事项中说的,必须是8的倍数,一字节就是8位,也就是8的倍数。
如果还没懂,可见下图:
3.4 查找(bitpos)
BITPOS key bit [start] [end]
返回第一个置为bit的二进制位的位置,默认检测整个Bitmaps,也可以通过start和end参数指定查询范围。
注意:start和end是字节索引,因此每增加1 代表的是增加一个字符,也就是8位,所以位的查询范围必须是8的倍数。
示例:
1 | |
3.5 位运算(bitop)
BITOP operation destkey key [key …]
其中,operation可以为:and、or、xor、not。如下:
- BITOP AND destkey key [key …] ,对一个或多个 key 求逻辑并,并将结果保存到 destkey。
- BITOP OR destkey key [key …] ,对一个或多个 key 求逻辑或,并将结果保存到 destkey。
- BITOP XOR destkey key [key …] ,对一个或多个 key 求逻辑异或,并将结果保存到 destkey。
- BITOP NOT destkey key ,对给定 key 求逻辑非(取反),并将结果保存到 destkey。
当字符串长度不一致是,较短的那个字符串所缺失的部分会被看作0,空的key也会被看作是包含0的字符串序列。
示例:
1 | |
本文作者: 墨水记忆
本文链接: https://tothefor.com/DragonOne/345839637.html
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
