MySQL高级-简述SQL执行过程
本文最后更新于:August 13, 2022 pm
积土成山,风雨兴焉;积水成渊,蛟龙生焉;积善成德,而神明自得,圣心备焉。故不积跬步,无以至千里,不积小流无以成江海。齐骥一跃,不能十步,驽马十驾,功不在舍。面对悬崖峭壁,一百年也看不出一条裂缝来,但用斧凿,能进一寸进一寸,能进一尺进一尺,不断积累,飞跃必来,突破随之。
目录
逻辑结构
服务器处理客户端请求的简图

详细图(经典图)。需要注意的是,此图对于MySQL5.7是完美的;但对于MySQL8.0来说,则多了一个查询缓存(Caches & Buffers)

Connectors:MySQL服务器以外的客户端程序(与具体的语言相关)。
Management & Services & Utilities:基础服务组件。
连接层:客户端访问MySQL服务前,需要先建立TCP的连接。经过三次握手建立连接成功后,MySQL服务器对TCP传输过来的账号密码做身份认证、权限获取。
- Connection Pool:连接池。提供了多个用于客户端与服务器端交互的线程。
服务层:
SQL Interface:SQL接口。接受SQL指令,以及返回结果。
Parser:解析器。词法、语义解析,最后会生成一个语法树便于后续的查询优化。即将SQL进行拆分。如图。
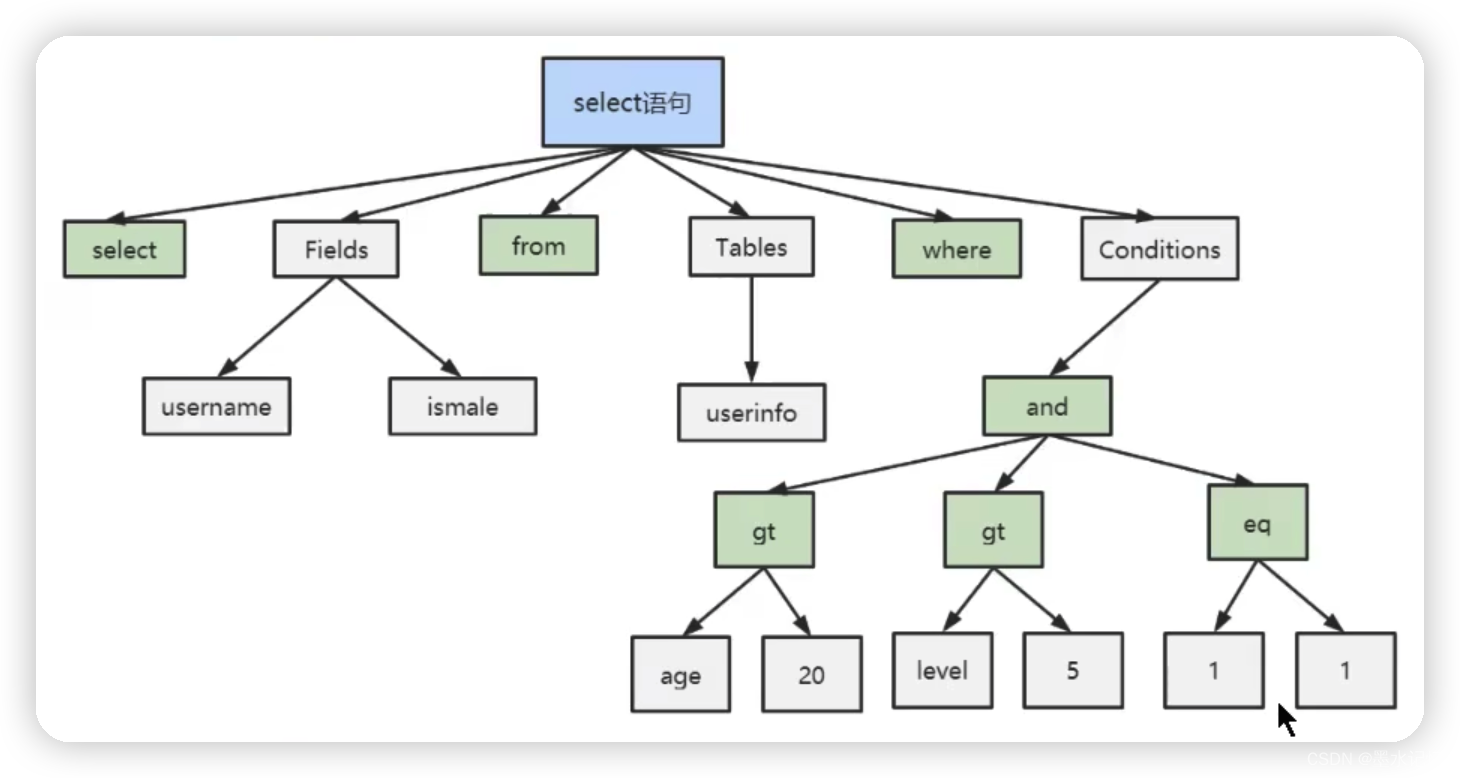
Optimizer:优化器。核心组件,SQL语句在语法解析后、查询之前会使用查询优化器确定SQL的执行路径,生成一个执行计划。一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到其中最好的执行计划。分为逻辑查询优化和物理查询优化
Caches & Buffers:查询缓存(MySQL8.0后被移除)。以key-value对方式进行缓存。SQL语句为key,结果为value。这里需要注意的是,这里的key必须严格的相等(空格的数量也必须一样,不能多不能少。否则将视为两个key)。
引擎层
- Pluggable Storage Englnes:插件式的存储引擎。与底层的文件系统进行交互。真正的负责了MySQL中数据的存储和提取,对物理服务器级别维护的底层数据执行操作。
File System:文件系统。
Files & Logs:日志文件。
以查询为例的执行顺序,见下图。

问题
在连接层中。一个系统只会和MySQL服务器建立一个连接吗?只能有一个系统和MySQL服务器建立连接吗?
- 都不是。多个系统都可以和MySQL服务器建立连接,每个系统建立的连接都不止一个。为了解决TCP无限创建与TCP频繁创建销毁带来的资源耗尽、性能下降问题。MySQL服务器里有专门的TCP连接池限制连接数,采用长连接模式复用TCP连接。
SQL执行流程
SQL语句中MySQL中的流程时:SQL语句 -> 查询缓存 -> 解析器 -> 优化器 -> 执行器。

更详细一点的图:

移除查询缓存的原因:命中率太低。
- 在MySQL中的查询缓存,不是缓存查询计划,而是查询对应的结果。这样就意味着只有相同的查询操作才会命中查询缓存。而两个查询请求中任何字符上的不同(空格、注释、大小写),都会导致缓存不会命中,所以MySQL的查询缓存命中率不高。
- 当调用某些系统函数时,可能同样的函数的两次调用会产生不同的结果。比如当以当前时间为值传入时,不同时间的两次查询也应该得到不同的结果,如果在第一次查询时就缓存了,那第二次查询的时候直接使用第一次查询的结果就是错误的。
- 缓存失效。MySQL的缓存系统会监测涉及到的每张表,只要该表的结构或者数据被修改,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除。对于更新频繁的数据库来说,查询缓存的命中率会非常低。
SQL语句的执行分析
使用命令查看是否开启计划,开启它可以让MySQL收集在SQL执行时所用到的资源情况。
1 | |
结果为0则表示关闭,现在进行设置为开启状态:
1 | |
执行后再次查看即为开启状态(1)。查看最近使用的命令:
1 | |
再使用命令进行查看执行对应SQL语句时的耗时:
1 | |
如果开启了查询缓存,那么在执行两次相同的SQL语句后,使用上面的方式查看耗时时,会发现第一次耗时长且步骤多;第二次相较于第一次而言会少很多。(提示:MySQL8.0中已经移除了,没有办法开启。所以两次效果相近)
本文作者: 墨水记忆
本文链接: https://tothefor.com/DragonOne/424f774.html
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
