本文最后更新于:April 11, 2022 pm
我相信大家都看过很多的关于线程池的文章,基本上也是面试的时候必问的,如果你在看过很多文章以后,还是一知半解的,那希望这篇文章能让你真正的掌握好 Java 线程池。
本文一大重点是源码解析,同时会有少量篇幅介绍线程池设计思想以及作者 Doug Lea 实现过程中的一些巧妙用法。本文还是会一行行关键代码进行分析,目的是为了让那些自己看源码不是很理解的同学可以得到参考。
线程池是非常重要的工具,如果你要成为一个好的工程师,还是得比较好地掌握这个知识,很多线上问题都是因为没有用好线程池导致的。即使你为了谋生,也要知道,这基本上是面试必问的题目,而且面试官很容易从被面试者的回答中捕捉到被面试者的技术水平。
本文略长,建议在 pc 上阅读,边看文章边翻源码(Java7 和 Java8 都一样),建议想好好看的读者抽出至少 30 分钟的整块时间来阅读。当然,如果读者仅为面试准备,可以直接滑到最后的总结 部分。
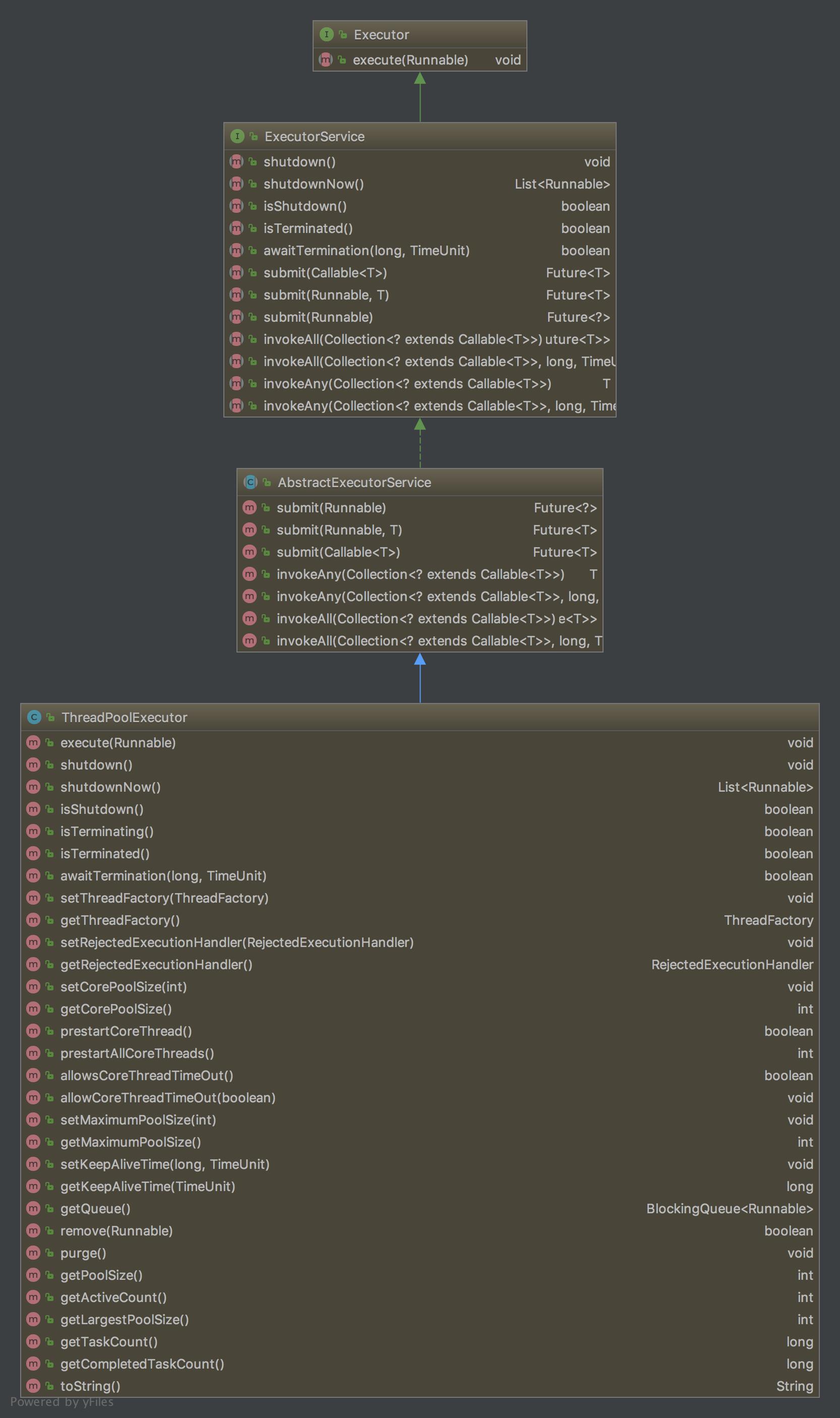
目录 总览 开篇来一些废话。下图是 java 线程池几个相关类的继承结构:
先简单说说这个继承结构,Executor 位于最顶层,也是最简单的,就一个 execute(Runnable runnable) 接口方法定义。
ExecutorService 也是接口,在 Executor 接口的基础上添加了很多的接口方法,所以一般来说我们会使用这个接口 。
然后再下来一层是 AbstractExecutorService,从名字我们就知道,这是抽象类,这里实现了非常有用的一些方法供子类直接使用,之后我们再细说。
然后才到我们的重点部分 ThreadPoolExecutor 类,这个类提供了关于线程池所需的非常丰富的功能。
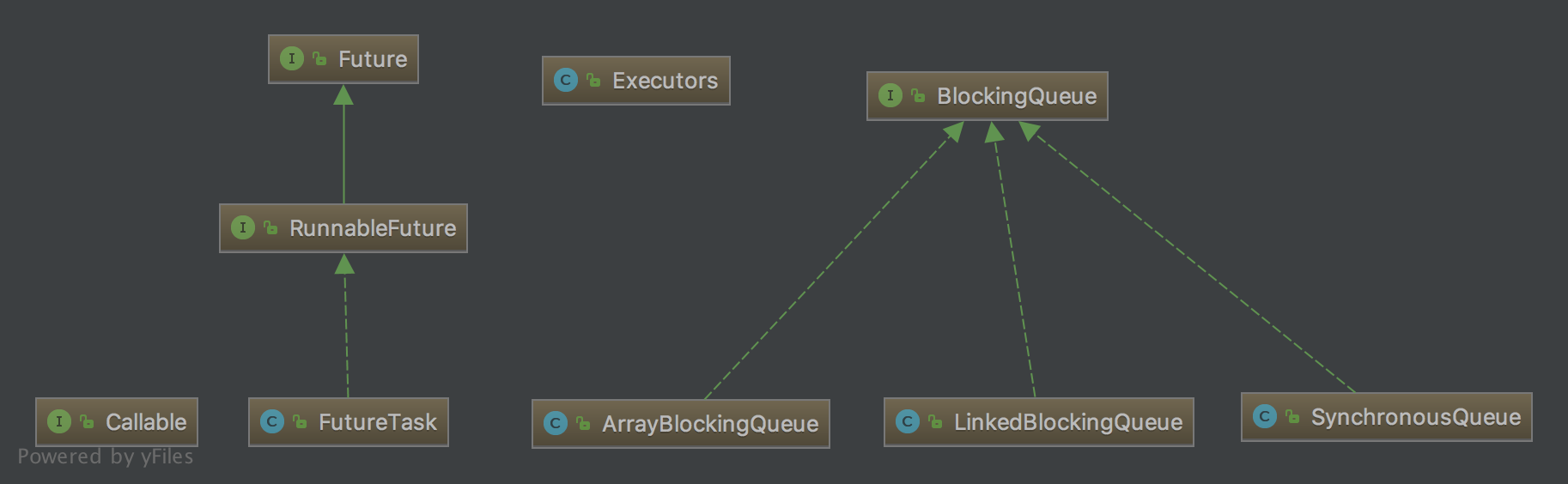
另外,我们还涉及到下图中的这些类:
同在并发包中的 Executors 类,类名中带字母 s,我们猜到这个是工具类,里面的方法都是静态方法,如以下我们最常用的用于生成 ThreadPoolExecutor 的实例的一些方法:
public static ExecutorService newCachedThreadPool () return new ThreadPoolExecutor(0 , Integer.MAX_VALUE,60L , TimeUnit.SECONDS,new SynchronousQueue<Runnable>());public static ExecutorService newFixedThreadPool (int nThreads) return new ThreadPoolExecutor(nThreads, nThreads,0L , TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
另外,由于线程池支持获取线程执行的结果 ,所以,引入了 Future 接口,RunnableFuture 继承自此接口,然后我们最需要关心的就是它的实现类 FutureTask。到这里,记住这个概念,在线程池的使用过程中,我们是往线程池提交任务(task),使用过线程池的都知道,我们提交的每个任务是实现了 Runnable 接口的,其实就是先将 Runnable 的任务包装成 FutureTask,然后再提交到线程池。这样,读者才能比较容易记住 FutureTask 这个类名:它首先是一个任务(Task),然后具有 Future 接口的语义,即可以在将来(Future)得到执行的结果。
当然,线程池中的 BlockingQueue 也是非常重要的概念,如果线程数达到 corePoolSize,我们的每个任务会提交到等待队列中,等待线程池中的线程来取任务并执行。这里的 BlockingQueue 通常我们使用其实现类 LinkedBlockingQueue、ArrayBlockingQueue 和 SynchronousQueue,每个实现类都有不同的特征,使用场景之后会慢慢分析。想要详细了解各个 BlockingQueue 的读者,可以参考我的前面的一篇对 BlockingQueue 的各个实现类进行详细分析的文章。
把事情说完整:除了上面说的这些类外,还有一个很重要的类,就是定时任务实现类 ScheduledThreadPoolExecutor,它继承自本文要重点讲解的 ThreadPoolExecutor,用于实现定时执行。不过本文不会介绍它的实现,我相信读者看完本文后可以比较容易地看懂它的源码。
以上就是本文要介绍的知识,废话不多说,开始进入正文。
Executor 接口 public interface Executor void execute (Runnable command)
我们可以看到 Executor 接口非常简单,就一个 void execute(Runnable command) 方法,代表提交一个任务。为了让大家理解 java 线程池的整个设计方案,我会按照 Doug Lea 的设计思路来多说一些相关的东西。
我们经常这样启动一个线程:
new Thread(new Runnable(){
用了线程池 Executor 后就可以像下面这么使用:
Executor executor = anExecutor;new RunnableTask1());new RunnableTask2());
如果我们希望线程池同步执行每一个任务,我们可以这么实现这个接口:
class DirectExecutor implements Executor public void execute (Runnable r)
我们希望每个任务提交进来后,直接启动一个新的线程来执行这个任务,我们可以这么实现:
class ThreadPerTaskExecutor implements Executor public void execute (Runnable r) new Thread(r).start();
我们再来看下怎么组合两个 Executor 来使用,下面这个实现是将所有的任务都加到一个 queue 中,然后从 queue 中取任务,交给真正的执行器执行,这里采用 synchronized 进行并发控制:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class SerialExecutor implements Executor final Queue<Runnable> tasks = new ArrayDeque<Runnable>();final Executor executor;this .executor = executor;public synchronized void execute (final Runnable r) new Runnable() {public void run () try {finally {if (active == null ) {protected synchronized void scheduleNext () if ((active = tasks.poll()) != null ) {
当然了,Executor 这个接口只有提交任务的功能,太简单了,我们想要更丰富的功能,比如我们想知道执行结果、我们想知道当前线程池有多少个线程活着、已经完成了多少任务等等,这些都是这个接口的不足的地方。接下来我们要介绍的是继承自 Executor 接口的 ExecutorService 接口,这个接口提供了比较丰富的功能,也是我们最常使用到的接口。
ExecutorService 一般我们定义一个线程池的时候,往往都是使用这个接口:
ExecutorService executor = Executors.newFixedThreadPool(args...);
因为这个接口中定义的一系列方法大部分情况下已经可以满足我们的需要了。
那么我们简单初略地来看一下这个接口中都有哪些方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public interface ExecutorService extends Executor void shutdown () List<Runnable> shutdownNow () ;boolean isShutdown () boolean isTerminated () boolean awaitTermination (long timeout, TimeUnit unit) throws InterruptedException ;Future<T> submit (Callable<T> task) ;Future<T> submit (Runnable task, T result) ;throws InterruptedException;long timeout, TimeUnit unit)throws InterruptedException;T invokeAny (Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException ;T invokeAny (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException ;
这些方法都很好理解,一个简单的线程池主要就是这些功能,能提交任务,能获取结果,能关闭线程池,这也是为什么我们经常用这个接口的原因。
FutureTask 在继续往下层介绍 ExecutorService 的实现类之前,我们先来说说相关的类 FutureTask。
Future Runnable
我们知道,Runnable 的 void run() 方法是没有返回值的,所以,通常,如果我们需要的话,会在 submit 中指定第二个参数作为返回值:
<T> Future<T> submit (Runnable task, T result) ;
其实到时候会通过这两个参数,将其包装成 Callable。它和 Runnable 的区别在于 run() 没有返回值,而 Callable 的 call() 方法有返回值,同时,如果运行出现异常,call() 方法会抛出异常。
public interface Callable <V > V call () throws Exception ;
在这里,就不展开说 FutureTask 类了,因为本文篇幅本来就够大了,这里我们需要知道怎么用就行了。
下面,我们来看看 ExecutorService 的抽象实现 AbstractExecutorService 。
AbstractExecutorService AbstractExecutorService 抽象类派生自 ExecutorService 接口,然后在其基础上实现了几个实用的方法,这些方法提供给子类进行调用。
这个抽象类实现了 invokeAny 方法和 invokeAll 方法,这里的两个 newTaskFor 方法也比较有用,用于将任务包装成 FutureTask。定义于最上层接口 Executor中的 void execute(Runnable command) 由于不需要获取结果,不会进行 FutureTask 的包装。
需要获取结果(FutureTask),用 submit 方法,不需要获取结果,可以用 execute 方法。
下面,我将一行一行源码地来分析这个类,跟着源码来看看其实现吧:
Tips: invokeAny 和 invokeAll 方法占了这整个类的绝大多数篇幅,读者可以选择适当跳过,因为它们可能在你的实践中使用的频次比较低,而且它们不带有承前启后的作用,不用担心会漏掉什么导致看不懂后面的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 public abstract class AbstractExecutorService implements ExecutorService protected <T> RunnableFuture<T> newTaskFor (Runnable runnable, T value) {return new FutureTask<T>(runnable, value);protected <T> RunnableFuture<T> newTaskFor (Callable<T> callable) {return new FutureTask<T>(callable);public Future<?> submit(Runnable task) {if (task == null ) throw new NullPointerException();null );return ftask;public <T> Future<T> submit (Runnable task, T result) {if (task == null ) throw new NullPointerException();return ftask;public <T> Future<T> submit (Callable<T> task) {if (task == null ) throw new NullPointerException();return ftask;private <T> T doInvokeAny (Collection<? extends Callable<T>> tasks, boolean timed, long nanos) throws InterruptedException, ExecutionException, TimeoutException {if (tasks == null )throw new NullPointerException();int ntasks = tasks.size();if (ntasks == 0 )throw new IllegalArgumentException();new ArrayList<Future<T>>(ntasks);new ExecutorCompletionService<T>(this );try {null ;long lastTime = timed ? System.nanoTime() : 0 ;int active = 1 ;for (;;) {if (f == null ) {if (ntasks > 0 ) {else if (active == 0 )break ;else if (timed) {if (f == null )throw new TimeoutException();long now = System.nanoTime();else if (f != null ) {try {return f.get();catch (ExecutionException eex) {catch (RuntimeException rex) {new ExecutionException(rex);if (ee == null )new ExecutionException();throw ee;finally {for (Future<T> f : futures)true );public <T> T invokeAny (Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException {try {return doInvokeAny(tasks, false , 0 );catch (TimeoutException cannotHappen) {assert false ;return null ;public <T> T invokeAny (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {return doInvokeAny(tasks, true , unit.toNanos(timeout));public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)throws InterruptedException {if (tasks == null )throw new NullPointerException();new ArrayList<Future<T>>(tasks.size());boolean done = false ;try {for (Callable<T> t : tasks) {for (Future<T> f : futures) {if (!f.isDone()) {try {catch (CancellationException ignore) {catch (ExecutionException ignore) {true ;return futures;finally {if (!done)for (Future<T> f : futures)true );public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit)throws InterruptedException {if (tasks == null || unit == null )throw new NullPointerException();long nanos = unit.toNanos(timeout);new ArrayList<Future<T>>(tasks.size());boolean done = false ;try {for (Callable<T> t : tasks)long lastTime = System.nanoTime();while (it.hasNext()) {long now = System.nanoTime();if (nanos <= 0 )return futures;for (Future<T> f : futures) {if (!f.isDone()) {if (nanos <= 0 )return futures;try {catch (CancellationException ignore) {catch (ExecutionException ignore) {catch (TimeoutException toe) {return futures;long now = System.nanoTime();true ;return futures;finally {if (!done)for (Future<T> f : futures)true );
到这里,我们发现,这个抽象类包装了一些基本的方法,可是像 submit、invokeAny、invokeAll 等方法,它们都没有真正开启线程来执行任务,它们都只是在方法内部调用了 execute 方法,所以最重要的 execute(Runnable runnable) 方法还没出现,需要等具体执行器来实现这个最重要的部分,这里我们要说的就是 ThreadPoolExecutor 类了。
鉴于本文的篇幅,我觉得看到这里的读者应该已经不多了,大家都习惯了快餐文化。我写的每篇文章都力求让读者可以通过我的一篇文章而对相关内容有全面的了解,所以篇幅不免长了些。
ThreadPoolExecutor ThreadPoolExecutor 是 JDK 中的线程池实现,这个类实现了一个线程池需要的各个方法,它实现了任务提交、线程管理、监控等等方法。
我们可以基于它来进行业务上的扩展,以实现我们需要的其他功能,比如实现定时任务的类 ScheduledThreadPoolExecutor 就继承自 ThreadPoolExecutor。当然,这不是本文关注的重点,下面,还是赶紧进行源码分析吧。
首先,我们来看看线程池实现中的几个概念和处理流程。
我们先回顾下提交任务的几个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public Future<?> submit(Runnable task) {if (task == null ) throw new NullPointerException();null );return ftask;public <T> Future<T> submit (Runnable task, T result) {if (task == null ) throw new NullPointerException();return ftask;public <T> Future<T> submit (Callable<T> task) {if (task == null ) throw new NullPointerException();return ftask;
一个最基本的概念是,submit 方法中,参数是 Runnable 类型(也有Callable 类型),这个参数不是用于 new Thread(runnable ).start() 中的,此处的这个参数不是用于启动线程的,这里指的是任务 ,任务要做的事情是 run() 方法里面定义的或 Callable 中的 call() 方法里面定义的。
初学者往往会搞混这个,因为 Runnable 总是在各个地方出现,经常把一个 Runnable 包到另一个 Runnable 中。请把它想象成有个 Task 接口,这个接口里面有一个 run() 方法。
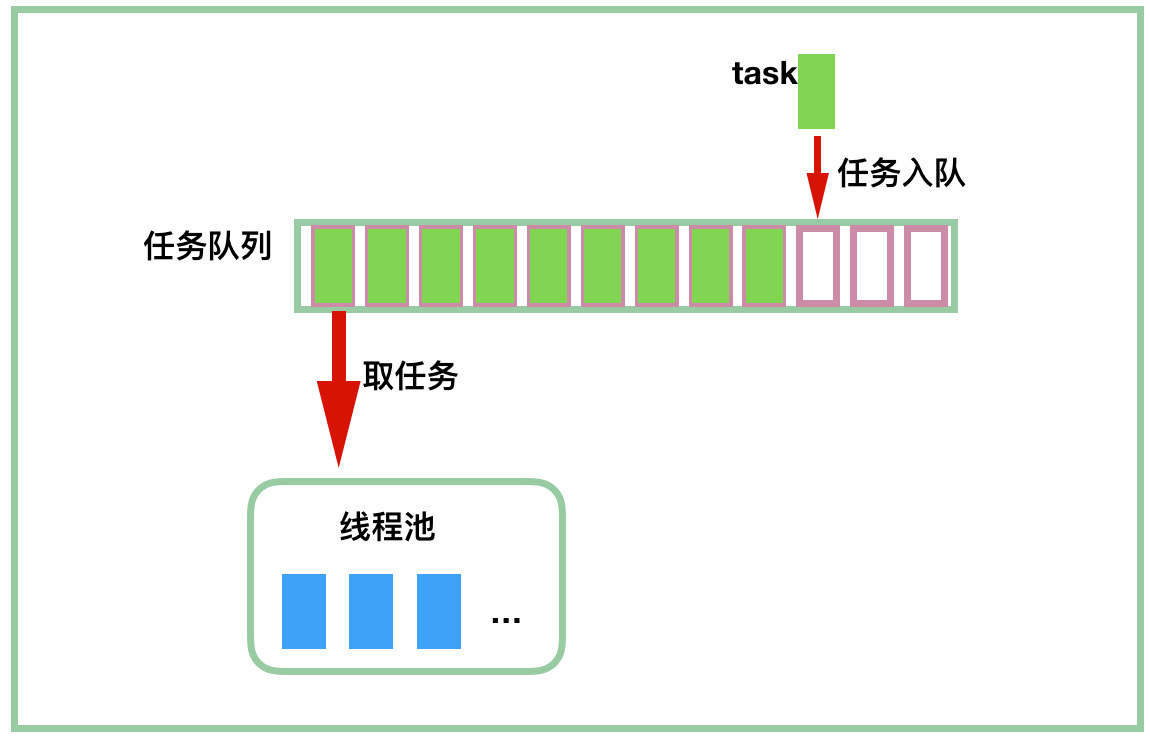
我们回过神来继续往下看,我画了一个简单的示意图来描述线程池中的一些主要的构件:
当然,上图没有考虑队列是否有界,提交任务时队列满了怎么办?什么情况下会创建新的线程?提交任务时线程池满了怎么办?空闲线程怎么关掉?这些问题下面我们会一一解决。
我们经常会使用 Executors 这个工具类来快速构造一个线程池,对于初学者而言,这种工具类是很有用的,开发者不需要关注太多的细节,只要知道自己需要一个线程池,仅仅提供必需的参数就可以了,其他参数都采用作者提供的默认值。
public static ExecutorService newFixedThreadPool (int nThreads) return new ThreadPoolExecutor(nThreads, nThreads,0L , TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());public static ExecutorService newCachedThreadPool () return new ThreadPoolExecutor(0 , Integer.MAX_VALUE,60L , TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
这里先不说有什么区别,它们最终都会导向这个构造方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) if (corePoolSize < 0 ||0 ||0 )throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null )throw new NullPointerException();this .corePoolSize = corePoolSize;this .maximumPoolSize = maximumPoolSize;this .workQueue = workQueue;this .keepAliveTime = unit.toNanos(keepAliveTime);this .threadFactory = threadFactory;this .handler = handler;
基本上,上面的构造方法中列出了我们最需要关心的几个属性了,下面逐个介绍下构造方法中出现的这几个属性:
corePoolSize
核心线程数,不要抠字眼,反正先记着有这么个属性就可以了。
maximumPoolSize
最大线程数,线程池允许创建的最大线程数。
workQueue
任务队列,BlockingQueue 接口的某个实现(常使用 ArrayBlockingQueue 和 LinkedBlockingQueue)。
keepAliveTime
空闲线程的保活时间,如果某线程的空闲时间超过这个值都没有任务给它做,那么可以被关闭了。注意这个值并不会对所有线程起作用,如果线程池中的线程数少于等于核心线程数 corePoolSize,那么这些线程不会因为空闲太长时间而被关闭,当然,也可以通过调用 allowCoreThreadTimeOut(true)使核心线程数内的线程也可以被回收。
threadFactory
用于生成线程,一般我们可以用默认的就可以了。通常,我们可以通过它将我们的线程的名字设置得比较可读一些,如 Message-Thread-1, Message-Thread-2 类似这样。
handler:
当线程池已经满了,但是又有新的任务提交的时候,该采取什么策略由这个来指定。有几种方式可供选择,像抛出异常、直接拒绝然后返回等,也可以自己实现相应的接口实现自己的逻辑,这个之后再说。
除了上面几个属性外,我们再看看其他重要的属性。
Doug Lea 采用一个 32 位的整数来存放线程池的状态和当前池中的线程数,其中高 3 位用于存放线程池状态,低 29 位表示线程数(即使只有 29 位,也已经不小了,大概 5 亿多,现在还没有哪个机器能起这么多线程的吧)。我们知道,java 语言在整数编码上是统一的,都是采用补码的形式,下面是简单的移位操作和布尔操作,都是挺简单的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0 ));private static final int COUNT_BITS = Integer.SIZE - 3 ;private static final int CAPACITY = (1 << COUNT_BITS) - 1 ;private static final int RUNNING = -1 << COUNT_BITS;private static final int SHUTDOWN = 0 << COUNT_BITS;private static final int STOP = 1 << COUNT_BITS;private static final int TIDYING = 2 << COUNT_BITS;private static final int TERMINATED = 3 << COUNT_BITS;private static int runStateOf (int c) return c & ~CAPACITY; }private static int workerCountOf (int c) return c & CAPACITY; }private static int ctlOf (int rs, int wc) return rs | wc; }private static boolean runStateLessThan (int c, int s) return c < s;private static boolean runStateAtLeast (int c, int s) return c >= s;private static boolean isRunning (int c) return c < SHUTDOWN;
上面就是对一个整数的简单的位操作,几个操作方法将会在后面的源码中一直出现,所以读者最好把方法名字和其代表的功能记住,看源码的时候也就不需要来来回回翻了。
在这里,介绍下线程池中的各个状态和状态变化的转换过程:
RUNNING:这个没什么好说的,这是最正常的状态:接受新的任务,处理等待队列中的任务
SHUTDOWN:不接受新的任务提交,但是会继续处理等待队列中的任务
STOP:不接受新的任务提交,不再处理等待队列中的任务,中断正在执行任务的线程
TIDYING:所有的任务都销毁了,workCount 为 0。线程池的状态在转换为 TIDYING 状态时,会执行钩子方法 terminated()
TERMINATED:terminated() 方法结束后,线程池的状态就会变成这个
RUNNING 定义为 -1,SHUTDOWN 定义为 0,其他的都比 0 大,所以等于 0 的时候不能提交任务,大于 0 的话,连正在执行的任务也需要中断。
看了这几种状态的介绍,读者大体也可以猜到十之八九的状态转换了,各个状态的转换过程有以下几种:
RUNNING -> SHUTDOWN:当调用了 shutdown() 后,会发生这个状态转换,这也是最重要的
(RUNNING or SHUTDOWN) -> STOP:当调用 shutdownNow() 后,会发生这个状态转换,这下要清楚 shutDown() 和 shutDownNow() 的区别了
SHUTDOWN -> TIDYING:当任务队列和线程池都清空后,会由 SHUTDOWN 转换为 TIDYING
STOP -> TIDYING:当任务队列清空后,发生这个转换
TIDYING -> TERMINATED:这个前面说了,当 terminated() 方法结束后
上面的几个记住核心的就可以了,尤其第一个和第二个。
另外,我们还要看看一个内部类 Worker,因为 Doug Lea 把线程池中的线程包装成了一个个 Worker,翻译成工人,就是线程池中做任务的线程。所以到这里,我们知道任务是 Runnable(内部变量名叫 task 或 command),线程是 Worker 。
Worker 这里又用到了抽象类 AbstractQueuedSynchronizer。题外话,AQS 在并发中真的是到处出现,而且非常容易使用,写少量的代码就能实现自己需要的同步方式(对 AQS 源码感兴趣的读者请参看我之前写的几篇文章)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 private final class Worker extends AbstractQueuedSynchronizer implements Runnable private static final long serialVersionUID = 6138294804551838833L ;final Thread thread;volatile long completedTasks;1 ); this .firstTask = firstTask;this .thread = getThreadFactory().newThread(this );public void run () this );
前面虽然啰嗦,但是简单。有了上面的这些基础后,我们终于可以看看 ThreadPoolExecutor 的 execute 方法了,前面源码分析的时候也说了,各种方法都最终依赖于 execute 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public void execute (Runnable command) if (command == null )throw new NullPointerException();int c = ctl.get();if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true ))return ;if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();if (! isRunning(recheck) && remove(command))else if (workerCountOf(recheck) == 0 )null , false );else if (!addWorker(command, false ))
对创建线程的错误理解:如果线程数少于 corePoolSize,创建一个线程,如果线程数在 [corePoolSize, maximumPoolSize] 之间那么可以创建线程或复用空闲线程,keepAliveTime 对这个区间的线程有效。
从上面的几个分支,我们就可以看出,上面的这段话是错误的。
上面这些一时半会也不可能全部消化搞定,我们先继续往下吧,到时候再回头看几遍。
这个方法非常重要 addWorker(Runnable firstTask, boolean core) 方法,我们看看它是怎么创建新的线程的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 private boolean addWorker (Runnable firstTask, boolean core) for (;;) {int c = ctl.get();int rs = runStateOf(c);if (rs >= SHUTDOWN &&null &&return false ;for (;;) {int wc = workerCountOf(c);if (wc >= CAPACITY ||return false ;if (compareAndIncrementWorkerCount(c))break retry;if (runStateOf(c) != rs)continue retry;boolean workerStarted = false ;boolean workerAdded = false ;null ;try {final ReentrantLock mainLock = this .mainLock;new Worker(firstTask);final Thread t = w.thread;if (t != null ) {try {int c = ctl.get();int rs = runStateOf(c);if (rs < SHUTDOWN ||null )) {if (t.isAlive())throw new IllegalThreadStateException();int s = workers.size();if (s > largestPoolSize)true ;finally {if (workerAdded) {true ;finally {if (! workerStarted)return workerStarted;
简单看下 addWorkFailed 的处理:
private void addWorkerFailed (Worker w) final ReentrantLock mainLock = this .mainLock;try {if (w != null )finally {
回过头来,继续往下走。我们知道,worker 中的线程 start 后,其 run 方法会调用 runWorker 方法:
public void run () this );
继续往下看 runWorker 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 final void runWorker (Worker w) null ;boolean completedAbruptly = true ;try {while (task != null || (task = getTask()) != null ) {if ((runStateAtLeast(ctl.get(), STOP) ||try {null ;try {catch (RuntimeException x) {throw x;catch (Error x) {throw x;catch (Throwable x) {throw new Error(x);finally {finally {null ;false ;finally {
我们看看 getTask() 是怎么获取任务的,这个方法写得真的很好,每一行都很简单,组合起来却所有的情况都想好了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 private Runnable getTask () boolean timedOut = false ; for (;;) {int c = ctl.get();int rs = runStateOf(c);if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {return null ;boolean timed; for (;;) {int wc = workerCountOf(c);if (wc <= maximumPoolSize && ! (timedOut && timed))break ;if (compareAndDecrementWorkerCount(c))return null ;if (runStateOf(c) != rs)continue retry;try {if (r != null )return r;true ;catch (InterruptedException retry) {false ;
到这里,基本上也说完了整个流程,读者这个时候应该回到 execute(Runnable command) 方法,看看各个分支,我把代码贴过来一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public void execute (Runnable command) if (command == null )throw new NullPointerException();int c = ctl.get();if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true ))return ;if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();if (! isRunning(recheck) && remove(command))else if (workerCountOf(recheck) == 0 )null , false );else if (!addWorker(command, false ))
上面各个分支中,有两种情况会调用 reject(command) 来处理任务,因为按照正常的流程,线程池此时不能接受这个任务,所以需要执行我们的拒绝策略。接下来,我们说一说 ThreadPoolExecutor 中的拒绝策略。
final void reject (Runnable command) this );
此处的 handler 我们需要在构造线程池的时候就传入这个参数,它是 RejectedExecutionHandler 的实例。
RejectedExecutionHandler 在 ThreadPoolExecutor 中有四个已经定义好的实现类可供我们直接使用,当然,我们也可以实现自己的策略,不过一般也没有必要。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public static class CallerRunsPolicy implements RejectedExecutionHandler public CallerRunsPolicy () public void rejectedExecution (Runnable r, ThreadPoolExecutor e) if (!e.isShutdown()) {public static class AbortPolicy implements RejectedExecutionHandler public AbortPolicy () public void rejectedExecution (Runnable r, ThreadPoolExecutor e) throw new RejectedExecutionException("Task " + r.toString() +" rejected from " +public static class DiscardPolicy implements RejectedExecutionHandler public DiscardPolicy () public void rejectedExecution (Runnable r, ThreadPoolExecutor e) public static class DiscardOldestPolicy implements RejectedExecutionHandler public DiscardOldestPolicy () public void rejectedExecution (Runnable r, ThreadPoolExecutor e) if (!e.isShutdown()) {
到这里,ThreadPoolExecutor 的源码算是分析结束了。单纯从源码的难易程度来说,ThreadPoolExecutor 的源码还算是比较简单的,只是需要我们静下心来好好看看罢了。
Executors 这节其实也不是分析 Executors 这个类,因为它仅仅是工具类,它的所有方法都是 static 的。
public static ExecutorService newFixedThreadPool (int nThreads) return new ThreadPoolExecutor(nThreads, nThreads,0L , TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
最大线程数设置为与核心线程数相等,此时 keepAliveTime 设置为 0(因为这里它是没用的,即使不为 0,线程池默认也不会回收 corePoolSize 内的线程),任务队列采用 LinkedBlockingQueue,无界队列。
过程分析:刚开始,每提交一个任务都创建一个 worker,当 worker 的数量达到 nThreads 后,不再创建新的线程,而是把任务提交到 LinkedBlockingQueue 中,而且之后线程数始终为 nThreads。
生成只有一个线程 的固定线程池,这个更简单,和上面的一样,只要设置线程数为 1 就可以了:
public static ExecutorService newSingleThreadExecutor () return new FinalizableDelegatedExecutorServicenew ThreadPoolExecutor(1 , 1 ,0L , TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));
生成一个需要的时候就创建新的线程,同时可以复用之前创建的线程(如果这个线程当前没有任务)的线程池:
public static ExecutorService newCachedThreadPool () return new ThreadPoolExecutor(0 , Integer.MAX_VALUE,60L , TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
核心线程数为 0,最大线程数为 Integer.MAX_VALUE,keepAliveTime 为 60 秒,任务队列采用 SynchronousQueue。
这种线程池对于任务可以比较快速地完成的情况有比较好的性能。如果线程空闲了 60 秒都没有任务,那么将关闭此线程并从线程池中移除。所以如果线程池空闲了很长时间也不会有问题,因为随着所有的线程都会被关闭,整个线程池不会占用任何的系统资源。
过程分析:我把 execute 方法的主体黏贴过来,让大家看得明白些。鉴于 corePoolSize 是 0,那么提交任务的时候,直接将任务提交到队列中,由于采用了 SynchronousQueue,所以如果是第一个任务提交的时候,offer 方法肯定会返回 false,因为此时没有任何 worker 对这个任务进行接收,那么将进入到最后一个分支来创建第一个 worker。之后再提交任务的话,取决于是否有空闲下来的线程对任务进行接收,如果有,会进入到第二个 if 语句块中,否则就是和第一个任务一样,进到最后的 else if 分支创建新线程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int c = ctl.get();if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true ))return ;if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();if (! isRunning(recheck) && remove(command))else if (workerCountOf(recheck) == 0 )null , false );else if (!addWorker(command, false ))
SynchronousQueue 是一个比较特殊的 BlockingQueue,其本身不储存任何元素,它有一个虚拟队列(或虚拟栈),不管读操作还是写操作,如果当前队列中存储的是与当前操作相同模式的线程,那么当前操作也进入队列中等待;如果是相反模式,则配对成功,从当前队列中取队头节点。具体的信息,可以看我的另一篇关于 BlockingQueue 的文章。
总结 我一向不喜欢写总结,因为我把所有需要表达的都写在正文中了,写小篇幅的总结并不能真正将话说清楚,本文的总结部分为准备面试的读者而写,希望能帮到面试者或者没有足够的时间看完全文的读者。
java 线程池有哪些关键属性?
corePoolSize,maximumPoolSize,workQueue,keepAliveTime,rejectedExecutionHandler
corePoolSize 到 maximumPoolSize 之间的线程会被回收,当然 corePoolSize 的线程也可以通过设置而得到回收(allowCoreThreadTimeOut(true))。
workQueue 用于存放任务,添加任务的时候,如果当前线程数超过了 corePoolSize,那么往该队列中插入任务,线程池中的线程会负责到队列中拉取任务。
keepAliveTime 用于设置空闲时间,如果线程数超出了 corePoolSize,并且有些线程的空闲时间超过了这个值,会执行关闭这些线程的操作
rejectedExecutionHandler 用于处理当线程池不能执行此任务时的情况,默认有抛出 RejectedExecutionException 异常 、忽略任务 、使用提交任务的线程来执行此任务 和将队列中等待最久的任务删除,然后提交此任务 这四种策略,默认为抛出异常。
说说线程池中的线程创建时机?
如果当前线程数少于 corePoolSize,那么提交任务的时候创建一个新的线程,并由这个线程执行这个任务;
如果当前线程数已经达到 corePoolSize,那么将提交的任务添加到队列中,等待线程池中的线程去队列中取任务;
如果队列已满,那么创建新的线程来执行任务,需要保证池中的线程数不会超过 maximumPoolSize,如果此时线程数超过了 maximumPoolSize,那么执行拒绝策略。
* 注意:如果将队列设置为无界队列,那么线程数达到 corePoolSize 后,其实线程数就不会再增长了。因为后面的任务直接往队列塞就行了,此时 maximumPoolSize 参数就没有什么意义。
Executors.newFixedThreadPool(…) 和 Executors.newCachedThreadPool() 构造出来的线程池有什么差别?
细说太长,往上滑一点点,在 Executors 的小节进行了详尽的描述。
任务执行过程中发生异常怎么处理?
如果某个任务执行出现异常,那么执行任务的线程会被关闭,而不是继续接收其他任务。然后会启动一个新的线程来代替它。
什么时候会执行拒绝策略?
workers 的数量达到了 corePoolSize(任务此时需要进入任务队列),任务入队成功,与此同时线程池被关闭了,而且关闭线程池并没有将这个任务出队,那么执行拒绝策略。这里说的是非常边界的问题,入队和关闭线程池并发执行,读者仔细看看 execute 方法是怎么进到第一个 reject(command) 里面的。
workers 的数量大于等于 corePoolSize,将任务加入到任务队列,可是队列满了,任务入队失败,那么准备开启新的线程,可是线程数已经达到 maximumPoolSize,那么执行拒绝策略。
因为本文实在太长了,所以我没有说执行结果是怎么获取的,也没有说关闭线程池相关的部分,这个就自行吧。