JAVA知识点-深入理解String字符串的创建和比较
本文最后更新于:May 15, 2022 pm
积土成山,风雨兴焉;积水成渊,蛟龙生焉;积善成德,而神明自得,圣心备焉。故不积跬步,无以至千里,不积小流无以成江海。齐骥一跃,不能十步,驽马十驾,功不在舍。面对悬崖峭壁,一百年也看不出一条裂缝来,但用斧凿,能进一寸进一寸,能进一尺进一尺,不断积累,飞跃必来,突破随之。
目录
所以示例均在JDK1.8环境下测试完成。
结论
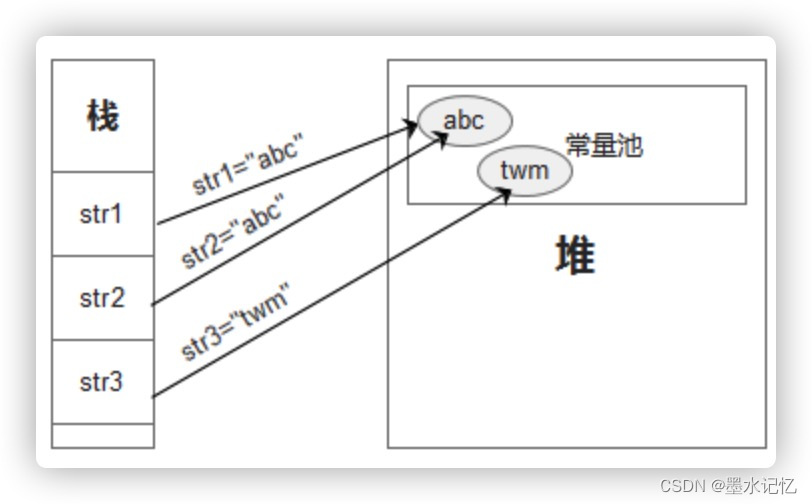
直接通过引号赋值的将会只在常量池中进行创建。如:String str = “abcd”; 则只会在常量池中创建一个字符串”abcd”。如果已经存在,则直接返回已经存在的字符串引用。如图。
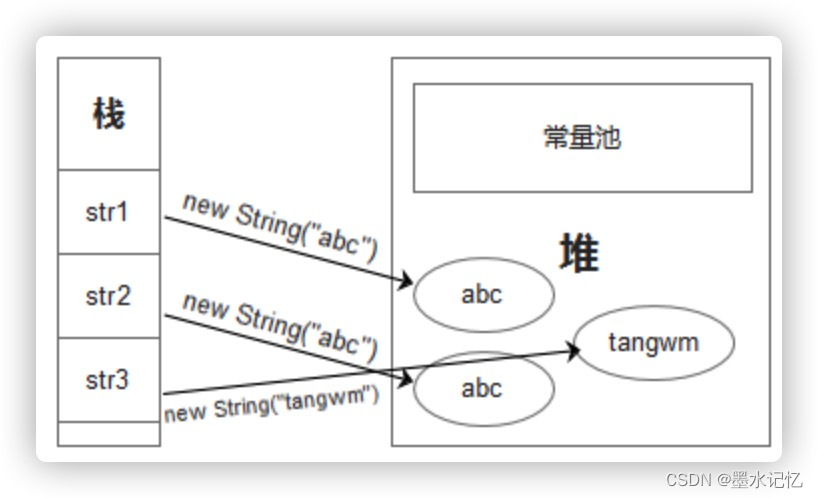
通过new String(“abcd”)的方式创建的字符串,会创建两个对象(可以理解为创建一个字符串对象会占用两块地方)。会创建在堆上,不管堆上是否已经存在了,都会进行创建。另一个是在常量池创建(这里是JDK1.6),但若常量池中已经存在了,则不会进行创建,而是直接返回该字符串。而在JDK1.7中,不存在,则创建;若存在则返回已经存在的引用。结合下图和后面两张图。(只要使用了new,便需要创建新的对象,所以两个new的字符串无论如何都不会相等)
String.intern()是一个本地方法(Native),具有返回值。它的作用在不同JDK中是不一样的。作用:
如果在常量池中已经存在了,则直接返回常量池中的引用。这是1.6 和1.7一样的。不同的是当不存在时的区别。
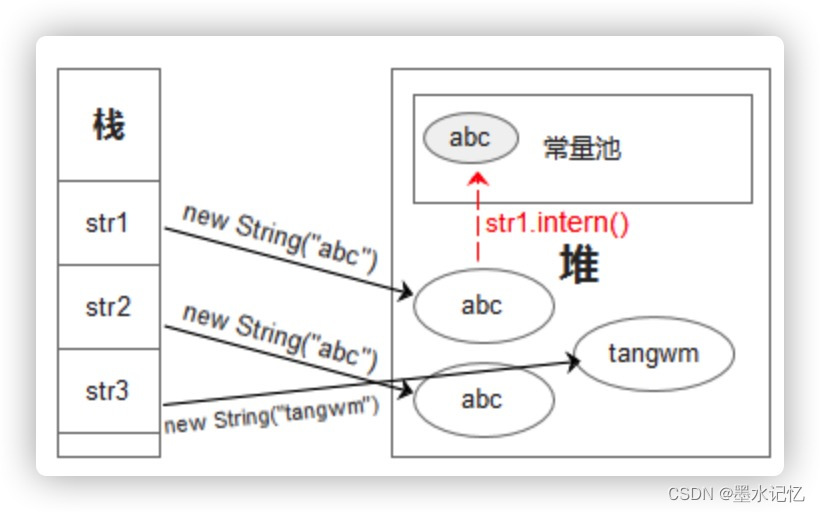
JDK1.6:将此String对象添加到常量池中(即副本),然后返回这个String对象的引用(此时引用的串在常量池)。如图。
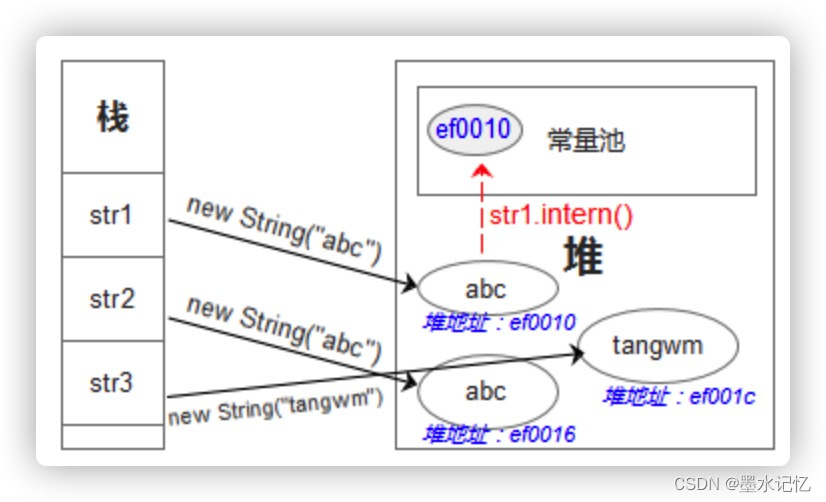
- JDK1.7:放入一个引用,指向堆中的String对象的地址,返回这个引用地址(此时引用的串在堆)。如图。
即在JDK1.6是在常量池中创建一个副本,会返回这个副本的引用;而在JDK1.7中并不是直接创建副本,而只是在常量池中生成一个对原字符串的引用。
个人简单理解intern(),就是用来把当前堆中字符串放到常量池里面的,如果当前字符串已经存在了,则返回常量池中字符串的引用;若不存在,则在常量池中设置一个引用来指向堆中的此字符串,后面用的时候都是指向堆中的此字符串。例如:String str = “abc”; 当调用str.intern()时,如果str这个字符串没有在常量池中存在,则创建一个引用来指向str,如果后面有其他字符串调用了intern()方法,而且也是”abc”,则直接返回这个引用给别的用;如果已经存在了,那就只能用别人的了。所以,感觉intern()就像是占地盘一样,第一个人来的时候,问这块地是谁的,没有人回答,那第一个人就占为己有;当第二个人来的时候再次询问这块地是谁的时候,就会有人回答他,说是第一个人的,后面如此循环。
个人总结
- 同过new的方式创建的字符串,会在常量池和堆中都会创建对象。
- 通过字符串的intern()方法获取到的只是一个引用。至于是当前对象的引用还是其他对象的引用,就要看调用此方法的时候常量池中是否已经存在了该字符串。如果已经存在了,那么获取的就是别的对象的引用;如果不存在就会创建一个指向当前字符串对象的引用并返回。
示例:
1 | |
再如:
1 | |
注意:第二行和第三行不可交换,否则答案完全相反。
拼接问题
直接赋值
分为没有被final修饰和被final修饰。首先看没有被final修饰。
未被final修饰的字符串
- 两个常量字符串拼接时会进行合并。如:String s4 = “ab”+”cd”;
- 常量字符串和变量拼接时(如:String str3=baseStr + “01”;)会调用stringBuilder.append()在堆上创建新的对象。
1 | |
其中,s5和s6是新创建的两个对象。可以自行Debug。所以其他和这两个相比一定是false。这里重要说的是s4。在编译阶段会直接将”ab”+”cd”合并成语句String str4=”abcd”,于是会去常量池中查找是否存在”abcd”,从而进行创建或引用(并没有在堆中进行创建)。而且String s4 = “ab”+”cd”;还会在常量池中进行创建”ab”和”cd”(不存在的情况下)。所以,这一句代码会创建三个字符串(都不存在的情况下):”ab”、”cd”、”abcd”。
被final修饰的字符串
被final修饰的会在编译期直接进行了常量替换。而非final字段则是在运行期进行赋值处理的(会调用stringBuilder.append()在堆上创建新的对象)。
1 | |
在编译时,直接将String str3=str1+str2;替换成了String str3=”ab”+”cd”;接下来就是和上面说的一样处理了。
2022年5月15日 补充
被 final 关键字修改之后的 String 会被编译器当做常量来处理,编译器在程序编译期就可以确定它的值,其效果就相当于访问常量。但如果编译器在运行时才能知道其确切值的话,就无法对其优化。如下代码:
1 | |
通过new
1 | |
这和直接赋值的有一些的区别。new String(“str”) + new String(“01”); 会先在堆中进行创建两个对象”str”和”01”,然后再去看常量池中是否有,没有则创建。处理完了后再进行连接得到字符串”str01”,然后就只会在堆中进行创建。所以,单独这一句代码执行完毕后,堆和常量池中的情况为:常量池中有:”str”,”01”,堆中有”str”,”01”,”str01”。
1 | |
第一句代码已经说了,然后第二句代码就是在常量池中创建字符串”str01”,所以两者是不同位置的两个字符串。执行str2.intern();时,因为前面在常量池中已经创建过字符串”str01”了,所以这里会返回已经存在的字符串引用,即str1。如下:
1 | |
但是,如果将str2.intern();换一个位置结果会不一样,如下:
1 | |
这是因为str2.intern();执行时会在常量池中判断是否存在字符串”str01”,因为不存在,所以会进行创建,而执行String str1 = “str01”;时在常量池中已经存在了字符串”str01”,所以返回的是已经存在的字符串的引用,即str2。
1 | |
理解示例
示例一
1 | |
解释
- 第一句代码是直接进行创建,是在常量池中进行创建。第二句代码是在堆上进行创建并且会在常量池中放入该字符串(堆上)的引用,但是,因为常量池已经存在了字符串”abcd”,所以在调用s2.intern()时返回的是s1的引用,见下面代码。而这里比较的是常量池中的字符串和堆上的字符串,所以两个字符串是在不同的地方,结果为false。
1 | |
示例二
1 | |
解释
- 第一句代码是在堆上进行创建同时在常量池中也会创建该字符串;第二句代码是返回该字符串在常量池中的字符串引用。所以,这是在两个不同的地方。
注意区别:
1 | |
个人理解:如果是new的,可以理解成在堆和常量池中都创建了对象;如果是intern,则只是在常量池中有一个指向堆中对象的引用。
示例三
1 | |
解释
String str2 = new String(“str”) + new String(“01”);执行后:常量池:”str”、”01”;堆:”str”、”01”、”str01”。
String str1 = “str01”;执行时,发现常量池中并没有字符串”str01”,所以直接创建。
String str3 = str2.intern();执行,发现已经有了”str01”,所以返回给str3的就是str1。所以相对为true。
示例四
1 | |
针对第二个个人理解:因为是通过new的方式创建的,所以会在堆和常量池中都会创建一个对象;而String str4 = “str01”;拿到的是常量池里面的,str3是堆里面的。 再如以下代码:
1 | |
示例五
1 | |
1 | |
本文作者: 墨水记忆
本文链接: https://tothefor.com/DragonOne/8baf6c9b.html
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
