本文最后更新于:March 10, 2023 pm
积土成山,风雨兴焉;积水成渊,蛟龙生焉;积善成德,而神明自得,圣心备焉。故不积跬步,无以至千里,不积小流无以成江海。齐骥一跃,不能十步,驽马十驾,功不在舍。面对悬崖峭壁,一百年也看不出一条裂缝来,但用斧凿,能进一寸进一寸,能进一尺进一尺,不断积累,飞跃必来,突破随之。
目录
Java8引入了@Contented这个新的注解来减少伪共享(False Sharing)的发生。使用@Contended来保证被标识的字段或者类不与其他字段出现内存争用。且该注解是从JDK8才开始出现的。
引例
示例一
正常使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| import java.util.concurrent.CountDownLatch;
public class Main {
public static void main(String[] args) throws Exception {
CountDownLatch countDownLatch = new CountDownLatch(2);
NoCacheLineFill[] arr = new NoCacheLineFill[2];
arr[0] = new NoCacheLineFill();
arr[1] = new NoCacheLineFill();
Thread threadA = new Thread(() -> {
for (long i = 0; i < 100_000_000L; i++) {
arr[0].x = i;
}
countDownLatch.countDown();
}, "ThreadA");
Thread threadB = new Thread(() -> {
for (long i = 0; i < 100_000_000L; i++) {
arr[1].x = i;
}
countDownLatch.countDown();
}, "ThreadB");
final long start = System.nanoTime();
threadA.start();
threadB.start();
countDownLatch.await();
final long end = System.nanoTime();
System.out.println("耗时:" + (end - start) / 1_000_000 + "毫秒");
}
}
class NoCacheLineFill {
public volatile long x = 1L;
}
|
输出:
处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| import java.util.concurrent.CountDownLatch;
public class Main {
public static void main(String[] args) throws Exception {
CountDownLatch countDownLatch = new CountDownLatch(2);
NoCacheLineFill[] arr = new NoCacheLineFill[2];
arr[0] = new NoCacheLineFill();
arr[1] = new NoCacheLineFill();
Thread threadA = new Thread(() -> {
for (long i = 0; i < 100_000_000L; i++) {
arr[0].x = i;
}
countDownLatch.countDown();
}, "ThreadA");
Thread threadB = new Thread(() -> {
for (long i = 0; i < 100_000_000L; i++) {
arr[1].x = i;
}
countDownLatch.countDown();
}, "ThreadB");
final long start = System.nanoTime();
threadA.start();
threadB.start();
countDownLatch.await();
final long end = System.nanoTime();
System.out.println("耗时:" + (end - start) / 1_000_000 + "毫秒");
}
}
class NoCacheLineFill {
public volatile long A, B, C, D, E, F, G;
public volatile long x = 1L;
public volatile long a, b, c, d, e, f, g;
}
|
输出:
📢注意:不同电脑,每次运行可能不一样。但两者之间的差距还是比较大的。
可以看见,上面的两段代码的运行时间差距是比较大的。而起作用的原因就是因为缓存行。
示例二
正常使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| import sun.misc.Contended;
import java.util.concurrent.CountDownLatch;
public class Main {
public static void main(String[] args) throws Exception {
CountDownLatch countDownLatch = new CountDownLatch(2);
NoCacheLineFill[] arr = new NoCacheLineFill[2];
arr[0] = new NoCacheLineFill();
arr[1] = new NoCacheLineFill();
Thread threadA = new Thread(() -> {
for (long i = 0; i < 100_000_000L; i++) {
arr[0].x = i;
}
countDownLatch.countDown();
}, "ThreadA");
Thread threadB = new Thread(() -> {
for (long i = 0; i < 100_000_000L; i++) {
arr[1].x = i;
}
countDownLatch.countDown();
}, "ThreadB");
final long start = System.nanoTime();
threadA.start();
threadB.start();
countDownLatch.await();
final long end = System.nanoTime();
System.out.println("耗时:" + (end - start) / 1_000_000 + "毫秒");
}
}
class NoCacheLineFill {
public volatile long x = 1L;
}
|
输出:
使用@Contended注解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| import sun.misc.Contended;
import java.util.concurrent.CountDownLatch;
public class Main {
public static void main(String[] args) throws Exception {
CountDownLatch countDownLatch = new CountDownLatch(2);
NoCacheLineFill[] arr = new NoCacheLineFill[2];
arr[0] = new NoCacheLineFill();
arr[1] = new NoCacheLineFill();
Thread threadA = new Thread(() -> {
for (long i = 0; i < 100_000_000L; i++) {
arr[0].x = i;
}
countDownLatch.countDown();
}, "ThreadA");
Thread threadB = new Thread(() -> {
for (long i = 0; i < 100_000_000L; i++) {
arr[1].x = i;
}
countDownLatch.countDown();
}, "ThreadB");
final long start = System.nanoTime();
threadA.start();
threadB.start();
countDownLatch.await();
final long end = System.nanoTime();
System.out.println("耗时:" + (end - start) / 1_000_000 + "毫秒");
}
}
class NoCacheLineFill {
@Contended
public volatile long x = 1L;
}
|
如果想要@Contended注解起作用,需要在启动时添加JVM参数:
输出:
CPU缓存机制
CPU是计算机的大脑,所有的程序,最终都要变成CPU指令在CPU中去执行。CPU的计算速度是非常快的,但是,程序必须存储在存储介质中,程序启动之后被加载到内存中才能执行。但是内存的读取速度和CPU的计算速度之间存在非常大的差异。那么为了解决这个计算速度之间的差异,就在CPU上增加了缓存来解决这个问题。通常情况下,CPU是三级缓存结构,如下图:
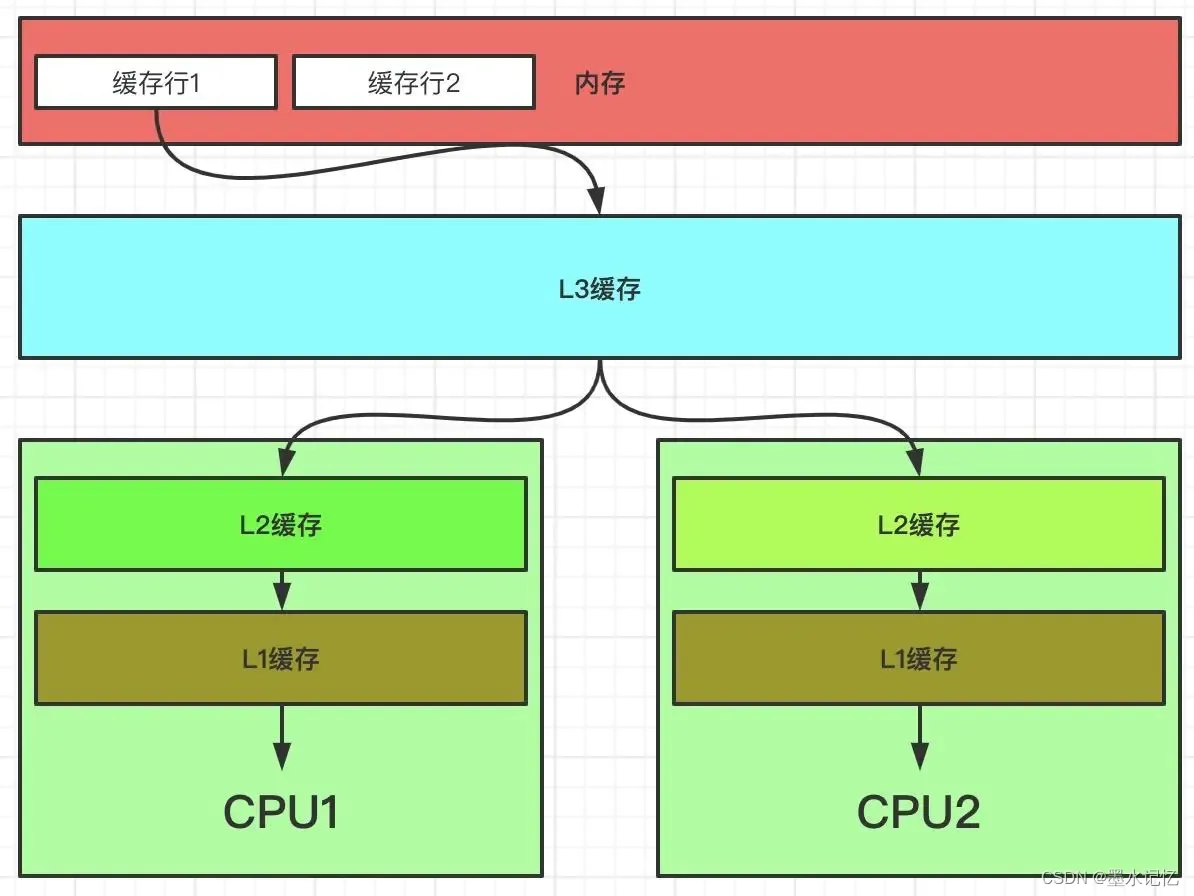
越靠近CPU的缓存,其容量就越小,但是其速度就越快。所以实际上L1的容量是最小的,这取决于CPU的具体型号。
缓存行
为了提高IO效率,CPU每次从内存读取数据并不是只读取我们需要计算的数据,而是将我们需要的数据周围的64个字节(intel处理器的缓存行是64字节)的数据一次性全部读取到缓存中。这64个字节的数据就称为一个缓存行(Cache line)。即:一个缓存行可以存放多个数据。
- 缓存一致性是根据缓存行(Cache line)为单元来进行同步的,即缓存中的传输单元为缓存行,CPU核心间交换数据是以缓存行为最小单位的,一个缓存行大小一般为64Byte。
- 缓存行内的内容一发生变化,就需要进行缓存同步。即使使用的不是同一个数据,但只要他们在同一个缓存行中,就会进行同步。
伪共享
了解伪共享之前,先看看什么是真共享。
- 真共享:一个蛋糕盒中只有一个大蛋糕,两个人吃。不同CPU的寄存器中都到了同一个变量X。
- 伪共享:一个蛋糕盒中有两块蛋糕,一人一个。不同CPU的寄存器中用到了不同的变量,一个用到的是X,一个用到的是Y,并且X和Y在同一个缓存行中。
缓存行中的伪共享问题,简单的说就是,当CPU1对缓存行中的数据做了修改时,会通知CPU2,告诉他数据我修改了,你那边作废了,需要重新从内存读取。反之,CPU2对数据做出修改,CPU1也需要重新读取。这样就会导致大量的IO操作,导致性能降低。
伪共享解决办法
为了避免这种现象,我们需要想办法将这两个数据放到不同的缓存行中,这样就可以避免频繁的读取数据,增加性能。一种是:使用额外的字段来对齐缓存行;二种是:使用@Contended注解。
- 缓存行填充。(示例一)不论如何进行缓存行的划分,包括x在内的连续64Byte,也就是一个缓存行不可能存在另一个变量Y,同样变量Y所在的缓存行不可能存在x,这样就不存在伪共享的情况,他们之间就不需要考虑缓存一致性问题了,也就节省了时间。
- 使用@Contended注解。(示例二)但启动时需要添加JVM参数:-XX:-RestrictContended。
实际运用
- LongAdder类的add()方法中,有一个Cell类,该类就是被@Contented修饰的。
- ConcurrentHashMap的addCount()方法中,有一个CounterCell类,该类同样是被@Contented修饰的。
